The Smart Forager — Reinforcement Learning in GAMA
By Killian Trouillet
Welcome to the comprehensive tutorial on Reinforcement Learning with the GAMA platform. You will build a forager agent that learns to navigate toward food while avoiding obstacles — from a simple grid world to a continuous environment trained with Deep RL.
Part 1: Internal RL (GAML only)
Build a tabular Q-Learning agent entirely in GAML, step by step:
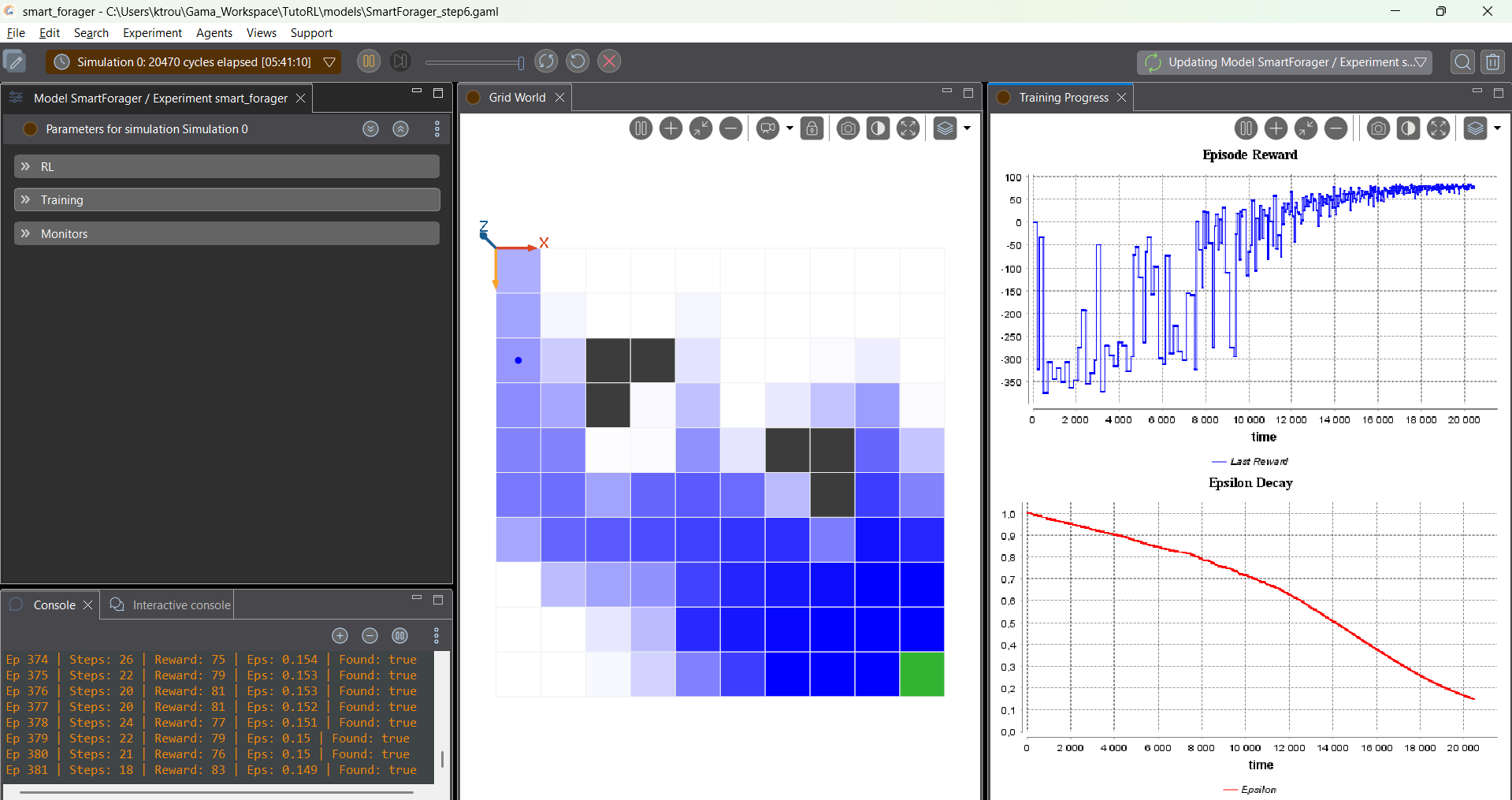
- Step 1: The Grid World — Create the 10×10 environment with food and obstacles.
- Step 2: The Forager Agent — Define a simple agent that moves randomly.
- Step 3: Rewards and Episodes — Implement the reward system and simulation resets.
- Step 4: The Q-Table — Set up the agent's memory using
map<string, float>. - Step 5: Q-Learning Algorithm — Implement the Bellman equation and ε-greedy policy.
- Step 6: Visualization & Automatic Test — Add charts, heatmaps, and evaluate the learned policy.
Part 2: Deep RL with Gymnasium — Continuous Forager
In this part, we move from the grid world to a continuous environment and train a neural network using PPO via the gama-gymnasium Python bridge.
- Step 7: Introduction & The Continuous World — Why Deep RL? Architecture overview. Continuous world setup.
- Step 8: The GymAgent Bridge — The bridge species, spaces, and GAMA↔Python communication.
- Step 9: Sensors, Movement & Rewards — Ray-cast sensors, velocity actions, reward shaping. Complete GAML model.
- Step 10: Headless Training with PPO — Python script, PPO explained, training process.
- Step 11: Testing in GAMA GUI — Load and visualize the trained policy. Summary.
Part 3: Multi-Agent Deep RL with PettingZoo — Cooperative Foragers
In this part, we extend the continuous world to multiple foragers that must cooperate: using gama-pettingzoo and independent PPO models, both agents must reach the food together.
- Step 12: From Single Agent to Multi-Agent — PettingZoo Parallel API,
PetzAgentbridge, cooperative reward design. - Step 13: The Multi-Agent GAML Model — Multi-forager species, observation sharing, reward logic.
- Step 14: Training Multiple Agents — Independent PPO,
PetzSingleAgentEnvGymnasium wrapper, alternating training rounds. - Step 15: Testing & Tutorial Summary — GUI testing, success criteria, recap of all 3 parts.